法律咨询场景中的大模型微调前评估

在面向法律咨询问答系统的大语言模型(LLM)开发中,团队往往需要决定是否对模型进行领域微调,以提升专业性和准确性。然而,微调不仅成本高昂,而且可能不是提升性能的唯一途径。在启动微调之前,优先从提示词工程、知识增强架构以及数据规模评估三个关键方面进行调研和验证,以确保微调的必要性和方向正确。这种预先评估有助于识别通过提示优化或系统架构改进即可解决的问题,从而节省时间与算力成本。下面我们将围绕这三大方面展开,提供技术逻辑、评估方法和实践建议,为法律产品团队和模型工程师在项目启动前提供参考。
提示词工程
技术逻辑: 提示词工程(Prompt Engineering)指的是精心设计和优化模型输入,以引导LLM产生更准确、有针对性的回答 。对于法律咨询场景,一个良好的提示词可以为模型提供明确的角色和上下文,例如强调“你是一名法律顾问”,并给出问题背景或期望的回答格式。这种方法的核心在于不改变模型本身,而是通过改进提问方式来提升输出质量 。其优势在于实现简单、成本低,因为无需重新训练模型即可获得改进的结果 。同时,提示词工程还能避免模型回答跑题或产生幻觉(hallucination),通过明确要求模型引用法条、逐步推理等方式来减少不相关或错误内容。
在决定微调之前,应该尝试通过专业提示词来测试模型在法律问答上的性能。具体步骤包括:
- 收集代表性咨询问题: 与法律产品团队合作,收集一组具有代表性的法律咨询问题及期望回答。这些问题应涵盖常见法律领域(如合同、劳动、婚姻等)的咨询场景。
- 设计多样化提示策略: 针对这些问题编写不同风格的提示,包括详细指示型提示(说明角色、步骤)、示例驱动型提示(Few-Shot给出范例问答)、链式思维提示(要求模型逐步推理)等。通过实验找出哪种提示最能引导模型得到准确答案 。
- 对比输出质量: 评估模型在不同提示下回答的准确性、专业性和一致性。例如,检查回答是否引用相关法律条文,逻辑推理是否清晰,结论是否正确。必要时请法律专业人员参与审核输出。
- 反复优化提示: 根据初步结果,不断修改提示词措辞和结构,观察输出改进情况。提示词工程通常需要迭代试验才能找到最佳提示 。如果通过优化提示已能满足大部分咨询场景的需求,那么模型或许无需大幅微调即可投入试用。
在法律场景中,提示设计可以非常具体。例如要求模型回答时列出相关法条依据,或者在回答末尾提醒用户咨询专业律师。这些细节都可以在提示中明确说明。实践中,建议团队准备一个“提示词手册”,总结哪些提示措辞对改善模型回答有效。 提到提示词工程的强大之处在于不需改动模型即可提升效果,但也强调了需要反复试验找到最佳提示。总之,充分利用提示词工程这一低成本手段,先榨取预训练模型的潜力,再决定是否需要进一步微调。
知识增强架构
技术逻辑: 知识增强架构通常是指基于检索增强的生成(Retrieval-Augmented Generation, RAG)系统。在法律咨询应用中,RAG通过将外部法律知识库与LLM结合,使模型能够检索相关法律条文或案例,再据此生成回答 。其工作流程通常是:用户提出法律问题,系统先在法律法规和案例数据库中检索出相关条文段落,将其与用户提问一并提供给LLM作为上下文,模型据此生成有依据的回答。这种架构解决了通用模型可能缺乏最新或本地法律知识的问题——模型不需要把所有法律知识都存储在参数中,而是可以实时查询知识库,从而保证答案的时效性和准确性 。对于经常变动的法规或专业性很强的法律领域,RAG架构尤为有效,因为它降低了模型产生不准确法律引用的风险,同时为回答提供了可追溯的依据。
评估方法: 在微调前,评估是否通过引入知识增强架构即可满足需求,可以从以下方面入手:
- 准备法律知识库: 整理一套权威的法律文本资料,例如现行法律法规条文、典型判例摘要、司法解释等,将其加载进检索系统(如向量数据库)。注意数据需要结构化处理,如按条款或判决要点分段存储,方便精准检索。
- 构建检索+生成原型: 实现一个简单的RAG原型:当用户提问时,先对问题进行向量化检索,从知识库获取相关内容(比如最相关的几条法条),然后将这些内容附加在提示中喂给LLM生成答案。观察模型在这种“开卷”的情况下回答是否更准确具体。
- 对比无检索的效果: 将RAG原型的回答与模型单纯依赖内部知识的回答进行对比评估。重点考察:RAG提供的回答中法律依据引用是否正确、内容是否更加详实。比如对于复杂的法律问题,未检索时模型可能泛泛而谈甚至张冠李戴,而通过检索相关法规后回答往往更切题。 指出在法律服务中,RAG可以调取相关案例法或法规以辅助模型回答法律查询。
- 评估系统复杂度和收益: 同时考虑实现成本:引入RAG需要维护更新法律数据库和检索服务,增加了一定系统复杂性。但如果评估发现其对回答准确性的提升显著(例如错误率降低、引用法条准确率提高),那么这一步是值得的。在法律咨询场景中,可靠性胜过一切,因此能用架构改进确保答案可靠,往往比单纯微调更能赢得用户信任。
实际建议: 如果评估结果表明RAG显著提升了模型法律问答的可靠性,团队应优先考虑将其纳入系统设计。一方面,可以减少对模型内部记忆法律知识的依赖,使模型专注于语言生成和逻辑推理部分;另一方面,法律数据库可以随时更新,保证信息与时俱进 。实践中,可使用现有开源工具(如 LangChain、LlamaIndex 等)快速搭建法律文档的向量检索模块,并结合现有的大模型 API 或开源模型完成回答生成。需要注意确保检索结果的质量,例如为每个用户问题检索足够但不冗余的条文段落。总之,知识增强架构在法律AI产品中往往是性价比很高的选择,在正式微调模型前应认真验证其效果。
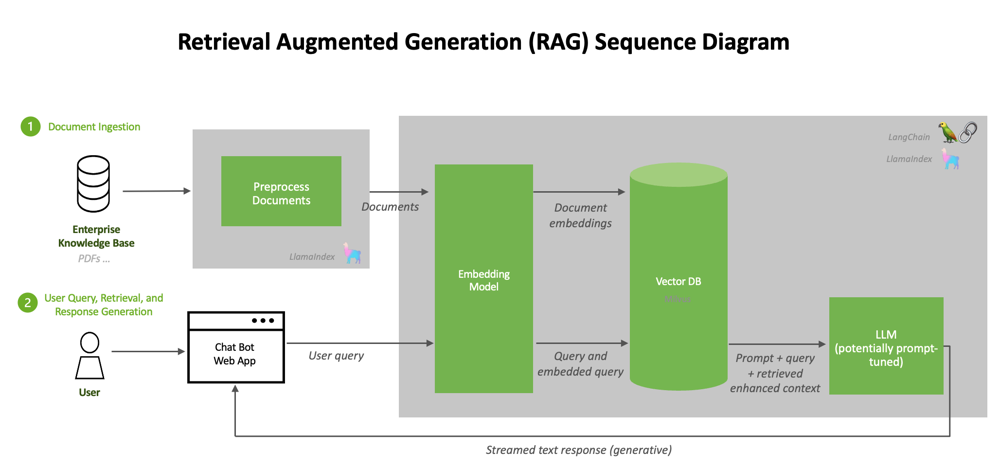
Retrieval Augmented Generation (RAG) 架构示意图:流程1(左)表示将法律知识文档预处理并向量化存入知识库;流程2(下)表示用户提问后系统检索相关向量并将结果与查询一同发送给LLM生成最终答案。该架构使LLM能够基于实时检索的知识回答问题,提高准确性和可解释性。
数据规模评估
技术逻辑: 在决定微调模型之前,必须验证手头法律领域数据是否足够支撑有效的微调。微调所需的数据不仅指数量,更涉及质量和覆盖面。如果数据量过少或不具代表性,强行微调可能导致模型过度拟合,反而降低泛化能力 。法律咨询问答系统通常需要大量高质量的问答对或法律文档摘要作为训练样本,以教会模型专业表达和推理。评估数据规模的逻辑在于:了解更多数据是否会显著提升模型性能,以及现有数据能否覆盖预期的咨询场景。需要综合考虑数据的清洁性、相关性和代表性 。清洁性指数据无严重错漏或噪声;相关性指数据的内容确实属于法律咨询范畴;代表性则意味着数据涵盖主要的法律领域和问题类型,避免偏科。
评估方法: 针对数据准备情况,采取以下评估步骤:
- 统计数据量与分布: 首先盘点用于微调的法律问答数据有多少条,以及来源构成。例如,包含多少对问答、涵盖哪些法律主题,每个主题的数据量占比如何。这一步可揭示数据是否存在样本量不足或领域分布不均衡的问题。
- 小规模微调试验: 为了评估现有数据的有效性,可在一小部分模型参数上进行试验性微调(例如采用LoRA等低成本微调方法)或者仅用部分数据微调模型 。然后将微调前后模型在验证集(未见过的法律问题)上的表现进行对比。如果少量数据的微调已经带来明显改进,说明数据质量较高且方向正确;反之,如果效果提升甚微,可能暗示数据不足或不符合模型需求。
- 学习曲线分析: 通过上述小规模试验,观察模型性能随训练样本数量的变化趋势 。如果加入更多样本后性能持续提升且未见饱和,说明增加数据可能进一步提高效果,此时应考虑扩充数据源。而如果性能很快趋于平稳甚至下降,表明现有数据已接近饱和或存在质量问题,与其一味增加数据量,不如优化数据质量或内容多样性。
- 检查数据质量与覆盖: 抽样审查一些训练数据的问答对,确保答案内容专业正确,无违背法律常识的错误。同时评估数据覆盖的场景:例如是否既有简明的法律咨询(如咨询离婚手续),也有复杂案例分析(如特定案情的法律意见)。如果某些高频咨询领域缺乏数据,模型微调后可能在该领域表现不佳,需要提前补足。
实际建议: 如果评估发现数据规模或质量不理想,有以下应对思路:一是尝试获取更多数据。例如利用公开的法律问答语料(法院问答文档、法律论坛问答等),或借助大模型本身生成一些模拟问答再由专家校验。 提示我们,并非所有项目都需要海量数据,小而精的数据集有时也能取得高性能。但关键在于确保数据贴近真实咨询需求且质量过关。二是考虑微调的方式:数据少可以采用增量训练、知识蒸馏、Few-Shot等替代方案,必要时结合RAG架构减轻模型记忆负担。总之,在启动大模型微调前,数据评估是一道不可跳过的关卡——只有当数据储备充足且合适,微调才能发挥预期效益。
结语
在法律咨询场景下开发大语言模型,贸然进行大规模微调并非总是最优策略。通过在前期仔细评估提示词工程、知识增强架构和数据规模这三大要素,团队可以更明智地制定方案:能用提示优化解决的,就不必动用微调;能通过检索增强获得可靠答案的,就让模型借力知识库;而当确需微调时,也已确保了高质量足量的数据支撑。这样的策略不仅降低研发风险和成本,也能产出更稳健可信的法律AI应用。希望本指南能够为法律产品团队与模型工程师在项目启动前提供有益的参考,打造出既技术先进又符合业务需求的法律咨询问答系统。
脱敏说明:本文所有出现的表名、字段名、接口地址、变量名、IP地址及示例数据等均非真实,仅用于阐述技术思路与实现步骤,示例代码亦非公司真实代码。示例方案亦非公司真实完整方案,仅为本人记忆总结,用于技术学习探讨。
• 文中所示任何标识符并不对应实际生产环境中的名称或编号。
• 示例 SQL、脚本、代码及数据等均为演示用途,不含真实业务数据,也不具备直接运行或复现的完整上下文。
• 读者若需在实际项目中参考本文方案,请结合自身业务场景及数据安全规范,使用符合内部命名和权限控制的配置。Data Desensitization Notice: All table names, field names, API endpoints, variable names, IP addresses, and sample data appearing in this article are fictitious and intended solely to illustrate technical concepts and implementation steps. The sample code is not actual company code. The proposed solutions are not complete or actual company solutions but are summarized from the author's memory for technical learning and discussion.
• Any identifiers shown in the text do not correspond to names or numbers in any actual production environment.
• Sample SQL, scripts, code, and data are for demonstration purposes only, do not contain real business data, and lack the full context required for direct execution or reproduction.
• Readers who wish to reference the solutions in this article for actual projects should adapt them to their own business scenarios and data security standards, using configurations that comply with internal naming and access control policies.版权声明:本文版权归原作者所有,未经作者事先书面许可,任何单位或个人不得以任何方式复制、转载、摘编或用于商业用途。
• 若需非商业性引用或转载本文内容,请务必注明出处并保持内容完整。
• 对因商业使用、篡改或不当引用本文内容所产生的法律纠纷,作者保留追究法律责任的权利。Copyright Notice: The copyright of this article belongs to the original author. Without prior written permission from the author, no entity or individual may copy, reproduce, excerpt, or use it for commercial purposes in any way.
• For non-commercial citation or reproduction of this content, attribution must be given, and the integrity of the content must be maintained.
• The author reserves the right to pursue legal action against any legal disputes arising from the commercial use, alteration, or improper citation of this article's content.Copyright © 1989–Present Ge Yuxu. All Rights Reserved.