A Deeper Dive into Probability: From Convergence to Core Concepts
Probability theory is the mathematical language of uncertainty, providing precise tools for reasoning about randomness. While introductory courses often focus on basic calculations, a deeper understanding requires grappling with subtle but fundamental concepts: What does it mean for random variables to “converge”? Why do limit theorems work, and when do they fail? How can we bound probabilities when we know little about the underlying distribution?
This post explores these questions through intuitive explanations backed by rigorous mathematics. We’ll journey from the philosophical question of whether coin flips truly approach 50% to practical tools for quantifying uncertainty in machine learning models.
Part 1: The Many Faces of Convergence
Scenario: Do Coin Flips Really Converge to the True Probability?
Imagine you flip a fair coin repeatedly, recording the proportion of heads after each toss. Intuition suggests this proportion should approach 50% as the number of flips increases. But what does “approach” actually mean? Probability theory offers several distinct notions of convergence, each with different implications.
Almost Sure Convergence: The Strongest Form
Almost sure convergence means that the random variable sequence converges to on “almost all” sample paths in the probability space. Intuitively, with probability 1, when is sufficiently large, will get arbitrarily close to and eventually stay close forever.
For coin flipping, this is the Strong Law of Large Numbers: the sample proportion of heads almost surely converges to the true probability 0.5. This is the strongest form of convergence and implies all other types.
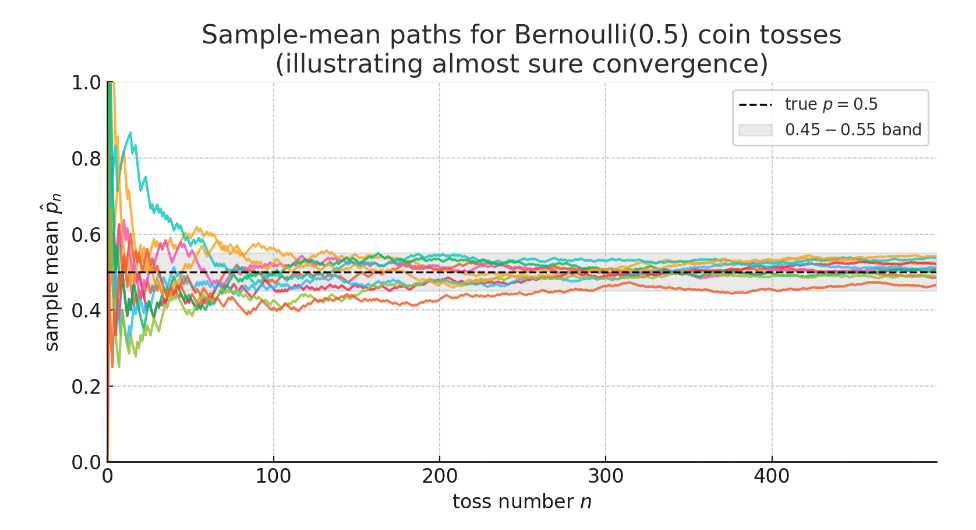
The figure above (10 colored curves) illustrates almost sure convergence:
Each curve represents one complete experiment—repeatedly flipping a fair coin, where the x-axis shows the number of tosses and the y-axis shows the proportion of heads in the first tosses.
- Black dashed line: True probability
- Gray band: The 0.45–0.55 interval, representing the intuitive “settling” range
Key observations:
- Initially, fluctuations are enormous (some curves even reach 0 or 1)
- As increases, all paths gradually stabilize and permanently stay within the gray band
- They never stray far from 0.5 again—this is the Strong Law of Large Numbers:
If we could draw infinitely many paths, almost every one would behave this way. Only paths with probability 0 might oscillate forever—but you’d essentially never observe them.
Convergence in Probability: The Practical Standard
Convergence in probability means that as , the probability that differs from by more than any small threshold approaches zero: .
This is weaker than almost sure convergence. While is usually very close to for large , occasional deviations are still possible. The Weak Law of Large Numbers proves that sample means converge in probability to their expected values.
A Classic Counterexample: Consider that takes value 1 with probability and 0 otherwise. Then , so (convergence in probability). However, since diverges, there will almost surely be infinitely many moments where , meaning the sample paths don’t actually converge to 0. This shows that convergence in probability doesn’t guarantee almost sure convergence.
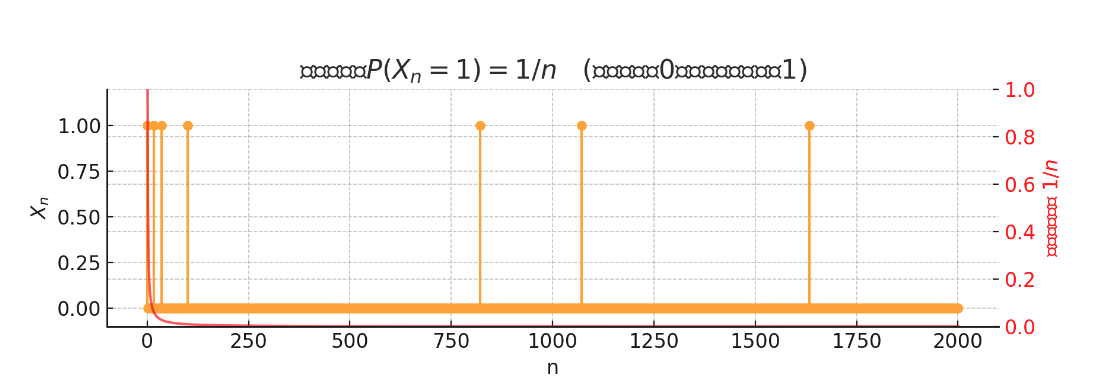
The figure shows yellow spikes representing the random variable —mostly taking value 0, but occasionally (with probability ) jumping to 1. The red curve shows how this probability decreases with .
-
As increases, the probability of getting 1 becomes smaller, satisfying: This confirms convergence in probability:
-
However, observing individual paths reveals: The spikes become sparser but never disappear—no matter how large gets, 1 will still occasionally appear, so sample paths don’t truly converge to 0.
This demonstrates that convergence in probability ≠ almost sure convergence.
Convergence in Distribution: The Weakest Form
Convergence in distribution means the cumulative distribution function of converges to that of . Roughly speaking, the probability distributions gradually become similar in shape, but we don’t care whether individual realizations are close.
This is the weakest form of convergence. The Central Limit Theorem is a prime example: regardless of the original distribution (as long as variance is finite and observations are i.i.d.), the standardized sample mean converges in distribution to a standard normal distribution.
Key Relationship: Almost sure convergence convergence in probability convergence in distribution. The reverse implications generally don’t hold, as our counterexamples demonstrate.
When Convergence of Moments Fails
Here’s a surprising fact: convergence in probability doesn’t guarantee convergence of variance. Consider this counterexample:
Define as: with probability , ; otherwise .
- Expectation:
- Variance: Since is either 0 or , we have . Thus
This converges to 0 in probability (since ), yet its variance approaches 1, not 0! The reason: although extreme values become increasingly rare, they also become increasingly extreme, maintaining their contribution to the variance.
This example reveals that different aspects of random variables can behave very differently during convergence, requiring careful analysis of what exactly is converging.
Part 2: The Limit Theorems That Shape Our World
The Central Limit Theorem: Why Standardization Matters
Scenario: Imagine rolling many dice and recording their sum. With 1 die, outcomes are uniform (1-6). With 2 dice, the sum distribution becomes triangular (2-12, centered at 7). With 10 dice, what happens? Intuition suggests the sum will approach a “bell curve.”
This intuition is formalized by the Central Limit Theorem (CLT): the sum (or average) of many independent, identically distributed random variables, when properly standardized, converges in distribution to a normal distribution—regardless of the original distribution shape.
Why Standardization? Without standardization, the sum would have mean and standard deviation , growing without bound. To observe a non-trivial limiting distribution, we center by subtracting and scale by dividing by :
The CLT states that as , converges in distribution to .
Practical Implication: For large , . This quantifies the sample mean’s fluctuation: it scales as , and the constant “3” corresponds to the 99.7% coverage of a normal distribution.
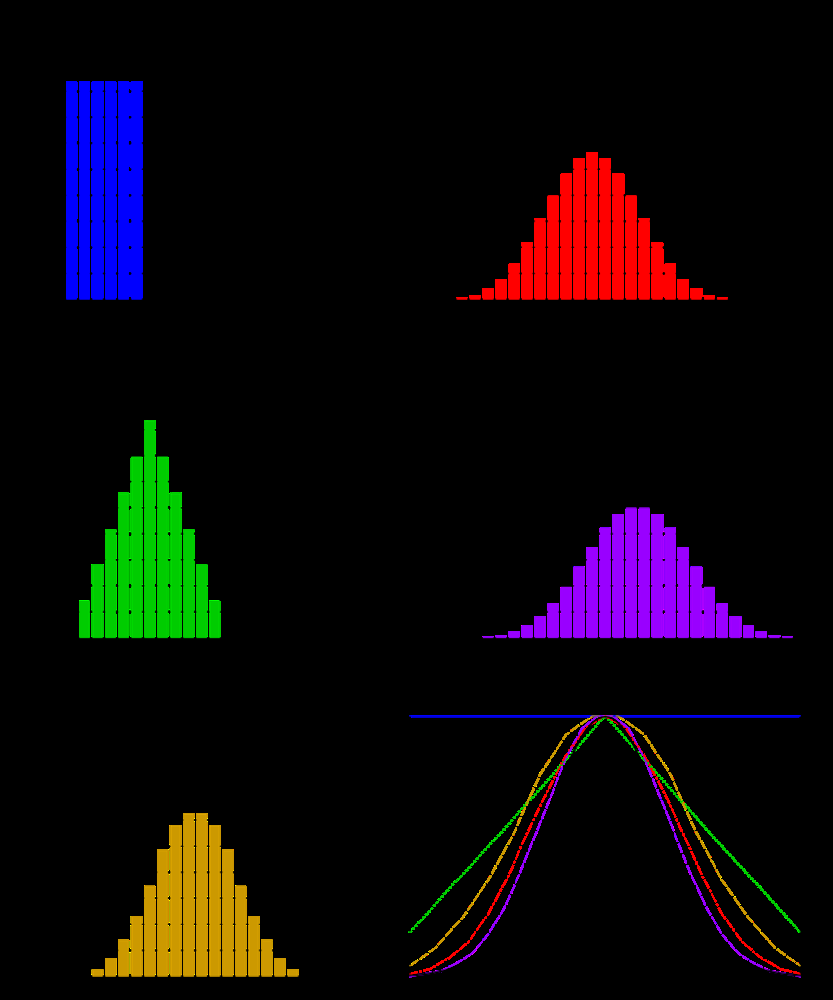
The figure shows how dice sums gradually approach a normal distribution. Top left: 1 die (uniform). Top right: 2 dice (triangular). Bottom left: 3 dice (more concentrated). Bottom right: smooth curves for 1, 2, 3, 4 dice sums with the standard normal curve overlaid (black). As the number of dice increases, the sum distribution progressively approaches normality.
Example: Suppose we measure machine part errors with unknown distribution but , mm. For parts, the average error satisfies . Therefore, . The probability that the average error falls within ±1 mm is about 99.7%.
From Binomial to Poisson: The Law of Rare Events
Scenario: A website has many users , each with a small probability of performing some action (e.g., logging in on a given day). How many users will perform this action?
When is large and is small while remains moderate, the binomial distribution can be approximated by a Poisson distribution. This is the law of rare events, fundamental in telecommunications, queueing theory, and reliability engineering.
Mathematical Development: Let . We have and (since when is small).
For the probability mass function:
As with fixed :
- Thus
- (using the standard limit)
Combining these: , which is the Poisson probability mass function.
Rule of Thumb: If and , the Poisson approximation to the binomial is quite accurate.
Part 3: A Practical Toolkit for Bounding Uncertainty
When we know little about a random variable’s distribution, probability inequalities provide crucial bounds on tail probabilities. Different inequalities require different assumptions and provide bounds of varying tightness.
Markov’s Inequality: The Most General Bound
For non-negative random variables :
Pros: Requires only knowledge of the mean. Cons: Often provides very loose bounds.
Example: If a model’s error has , then . This is an upper bound—the true probability might be much smaller.
Chebyshev’s Inequality: Leveraging Variance Information
For any random variable with finite variance:
Advantages: Doesn’t require non-negativity or boundedness, and typically gives tighter bounds than Markov when variance is known.
Example: If model error has and , then .
Hoeffding’s Inequality: The Power of Bounded Variables
For independent bounded random variables with :
This provides exponential concentration, making it extremely powerful for large .
Corrected Example: To ensure the deviation probability is below 5%:
- Hoeffding: Solving gives (approximately 185 samples)
- Chebyshev: With worst-case variance 0.25, solving gives
As increases, Hoeffding’s exponential advantage becomes dramatic: it provides decay versus Chebyshev’s decay.
When to Use Which Inequality?
- Markov: When you only know the mean and the variable is non-negative. The bound is often conservative but better than nothing.
- Chebyshev: When you know the variance but can’t guarantee boundedness. Provides universal tail control for any finite-variance distribution.
- Hoeffding: When variables are bounded and independent. Gives exponential concentration bounds, particularly powerful for large . Essential in machine learning generalization analysis and A/B testing.
Part 4: Properties of Foundational Distributions
The Memoryless Property: Does Waiting Longer Improve Your Chances?
Scenario: You’ve been waiting at a bus stop for 30 minutes. Someone says, “Don’t worry, you’ve waited so long that the bus must come soon!” Is this comfort mathematically justified?
If bus arrival times follow an exponential distribution, this intuition is wrong. The exponential distribution has the memoryless property: past waiting doesn’t affect future waiting.
Mathematical Definition: For any :
The probability of waiting an additional time units, given you’ve already waited units, equals the probability of initially waiting units.
Verification for Exponential Distribution: With :
Implications:
- In queueing systems with exponential service times, the system has no “memory” of how long you’ve waited
- This greatly simplifies Markov process analysis
- However, most real systems do exhibit aging effects, so exponential models are approximations
Working with the Standard Normal Distribution
Scenario: Statistics exams often ask: “Given , find .” Since normal distributions lack closed-form CDFs, we rely on standardization and tables.
The Standardization Process:
- Convert to standard normal: , where
- Rewrite the probability:
- Use the standard normal table to find
Key Techniques:
- For negative values: Use symmetry:
- For intervals:
- Remember the 68-95-99.7 rule: Approximately 68%, 95%, and 99.7% of data falls within 1, 2, and 3 standard deviations, respectively
Part 5: The Linear Algebra Backbone
Many advanced probability concepts, especially in multivariate settings or machine learning applications like Principal Component Analysis, rely heavily on linear algebra. Here’s an intuitive review of key concepts.
Understanding Matrix Properties Through Geometric Intuition
Scenario: Imagine a linear transformation acting on a 2D plane, stretching a square into a rectangle. What properties characterize this transformation?
-
Rank: The number of linearly independent rows/columns, measuring the dimensionality of the transformation’s output space. Rank means some dimensions are compressed (there exist non-zero vectors with ).
-
Determinant: Measures volume scaling with sign indicating orientation preservation. means the transformation compresses space to zero volume (rank deficiency).
-
Eigenvalues and Eigenvectors: Special directions where the transformation only scales: . Eigenvalues give scaling factors; eigenvectors show invariant directions.
-
Trace: Sum of diagonal elements, which equals the sum of all eigenvalues:
Key Relationships
For any matrix with eigenvalues :
- (sum of eigenvalues)
- (product of eigenvalues)
- Rank = number of non-zero eigenvalues
These relationships reveal deep connections: zero eigenvalues ⟺ zero determinant ⟺ rank deficiency ⟺ some directions compressed to zero.
Geometric Insight: For a diagonal matrix , the x-axis is stretched by factor 3, the y-axis by factor 2. Here, the coordinate axes are eigenvectors with eigenvalues 3 and 2. We have , , and rank = 2.
Conclusion
This journey through probability theory reveals how seemingly simple concepts like “convergence” hide subtle distinctions with profound practical implications. Understanding when the Central Limit Theorem applies, choosing appropriate probability inequalities, and recognizing the memoryless property’s implications are essential skills for modern data science and machine learning.
The interconnections between these concepts—from convergence modes through limit theorems to practical bounds—form the mathematical foundation that enables us to reason precisely about uncertainty. Whether you’re analyzing A/B test results, building machine learning models, or designing experiments, these tools provide the rigorous framework needed to transform data into reliable insights.
As we continue to grapple with increasingly complex data and models, returning to these fundamental principles ensures our conclusions rest on solid mathematical ground rather than intuitive but potentially misleading heuristics.
脱敏说明:本文所有出现的表名、字段名、接口地址、变量名、IP地址及示例数据等均非真实,仅用于阐述技术思路与实现步骤,示例代码亦非公司真实代码。示例方案亦非公司真实完整方案,仅为本人记忆总结,用于技术学习探讨。
• 文中所示任何标识符并不对应实际生产环境中的名称或编号。
• 示例 SQL、脚本、代码及数据等均为演示用途,不含真实业务数据,也不具备直接运行或复现的完整上下文。
• 读者若需在实际项目中参考本文方案,请结合自身业务场景及数据安全规范,使用符合内部命名和权限控制的配置。Data Desensitization Notice: All table names, field names, API endpoints, variable names, IP addresses, and sample data appearing in this article are fictitious and intended solely to illustrate technical concepts and implementation steps. The sample code is not actual company code. The proposed solutions are not complete or actual company solutions but are summarized from the author's memory for technical learning and discussion.
• Any identifiers shown in the text do not correspond to names or numbers in any actual production environment.
• Sample SQL, scripts, code, and data are for demonstration purposes only, do not contain real business data, and lack the full context required for direct execution or reproduction.
• Readers who wish to reference the solutions in this article for actual projects should adapt them to their own business scenarios and data security standards, using configurations that comply with internal naming and access control policies.版权声明:本文版权归原作者所有,未经作者事先书面许可,任何单位或个人不得以任何方式复制、转载、摘编或用于商业用途。
• 若需非商业性引用或转载本文内容,请务必注明出处并保持内容完整。
• 对因商业使用、篡改或不当引用本文内容所产生的法律纠纷,作者保留追究法律责任的权利。Copyright Notice: The copyright of this article belongs to the original author. Without prior written permission from the author, no entity or individual may copy, reproduce, excerpt, or use it for commercial purposes in any way.
• For non-commercial citation or reproduction of this content, attribution must be given, and the integrity of the content must be maintained.
• The author reserves the right to pursue legal action against any legal disputes arising from the commercial use, alteration, or improper citation of this article's content.Copyright © 1989–Present Ge Yuxu. All Rights Reserved.